

Hashing Fonksiyonları(Hashing Functions)
Veri yapıları üzerinde veri aramak zor bir
süreçtir. Bu konuyla ilgili çeşitli arama algoritmaları oluşturulmuş,
çeşitli veri yapıları kullanılmıştır.
Hashing ana amacı veri öyle yerleştirilmelidir ki arama
yapıldığında o adresi işaret etmelidir. Hashing yapısında bilgisayar bilimlerindeki
temel sorun sürekli dinamik olması yani ekleme ve çıkarma işlemlerinin sık sık
yapılması kaynaklıdır.
Belli sayılar olduğunu varsayılsın, bu sayıları
bir diziye yerleştirmek gerekiyor. Ancak temel hedef arama işlemini
kolaylaştırmak olmalıdır. Öncelikle sıralama algoritması kullanmak gerekir
diye düşünülebilir. Bu iyi bir fikir gibi görünse de temel amaç olan adrese
işaret etme durumunu gerçekleştiremeyecektir.

1- Sıralama Maliyeti:
Çok yüksek miktardaki sayıyı sıralamak zaten bir işlem ve süre maliyeti
getirecektir.
2- Ekleme/Çıkarma İşlemleri:
Özellikle dizi veri yapısı üzerinde ekleme/çıkarma yapmak zor bir işlemdir.
3- Arama Maliyeti:
Sayıların sıralı olması, o adreste hemen bulunacağı anlamına gelmez, arama algoritmasının
performansına bağlıdır.
Yukarıdaki 3 temel problem, hızlı bulma amacını
karşılamamaktadır.
Bu işlemler çözümlenirse, Hashing başta eklemek
istediğin sayıyı, yerleştirmek istediğin dizinin boyutuna göre modunu al, o
indise yerleştir. Arama yaparken de aradığın sayıyı dizinin boyutuna böl, o
indiste sayıyı bul.
Hashing
Simülasyonu
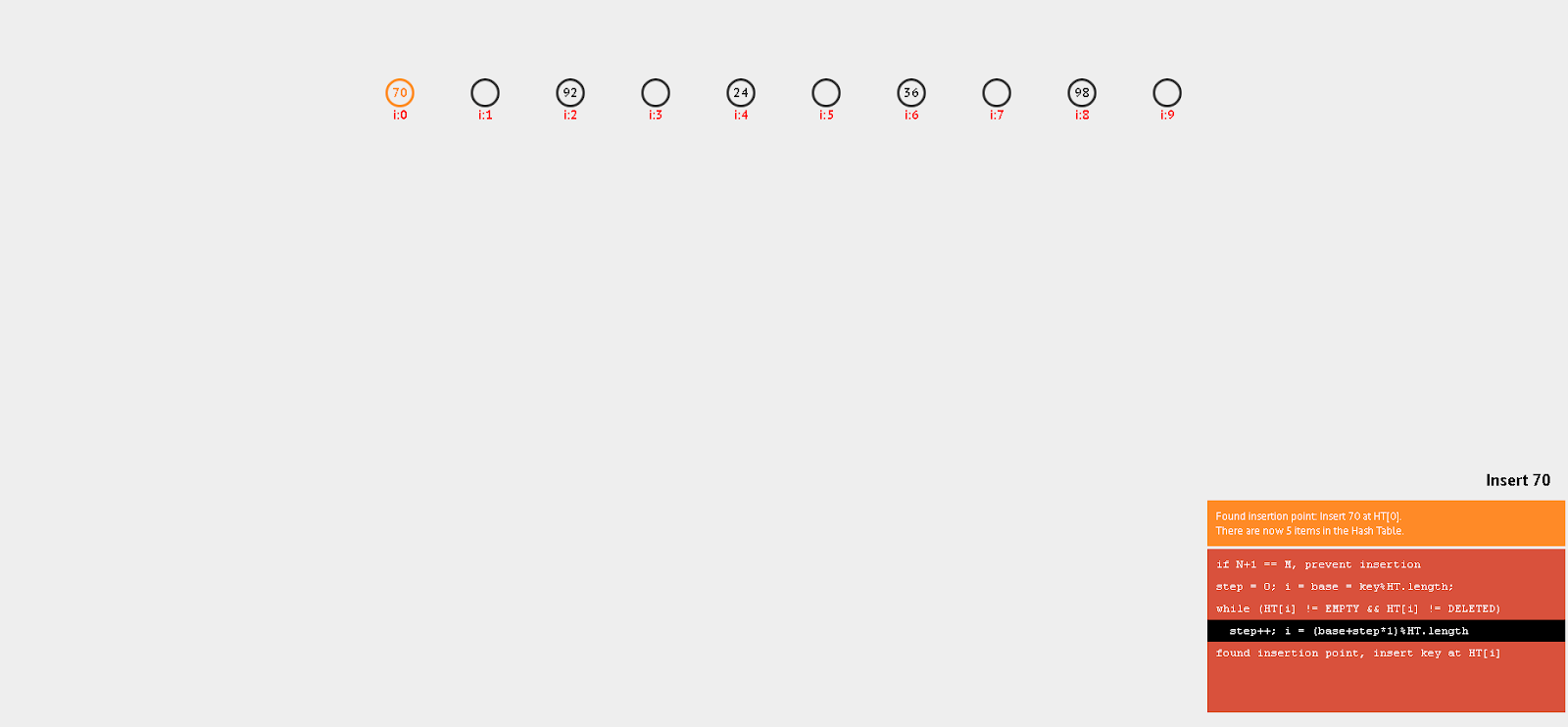
[ 24, 36, 98, 92, 70 ] sayılarını 10 boyutlu diziye
yerleştirildiğinde hangi indise yerleştireceğini şu şekilde bulunur.
 |
| Hashing Simülasyonu |
Görüldüğü üzere dizinin ilgili indislerine
sayıların yerleştirdiği görülüyor. Eklemek istenilen sayının, dizinin boyutuna
göre modunu alıp dizinin ilgili indisine sayıyı yerleştiriliyor.
Simülasyonda 92 sayısını aramak istenildiğinde bu
diziye tek tek bakılmayacaktır.102 sayısının 10’a göre modunu alındığında 2
olduğu görülür ve dizinin 2. indisine bakılır, İndiste 92 sayısını bulunur.
Diziye 224 sayısı eklensin.
224 sayısının 10’a göre modu alındığında sonucun 4 olduğunu görülür. Dizinin 4.
indisine gidilir, dizinin 4. indisi dolu, o halde ne yapmak gerekir? İşte
Hashing’i bilmek esasında bundan sonraki durumlar ile ilgili bir konudur. Genel
terminolojide bu duruma Collision(Çakışma) adı verilir. Hashing Collision
durumunda 3 değişik çözüm sunar.
Hashing Çakışma Çözümleri (Hashing Collision Solutions)
Eğer yerleştirilecek olan verinin yerinde başka
bir veri varsa aşağıdaki çözümler uygulanır.
- Seperate
Chaining
- Open
Addressing
Seperate
Chaining
Seperate Chaining aynı hash değeri üzerinde linked
list(bağlı liste) oluşturmayı hedefler. Yani başka bir hashing değerine elemanı
yerleştirmek yerine ilgili hashing değerinde yer alan sayı, yeni gelen sayıyı
işaret eder.
11 boyutlu bir diziye, 13 ve 35 sayılarını eklensin.
Dizinin boyutuna göre modu alındığında tüm sayılar için sonucun 2 olduğu
görülür. Yani dizinin 2. indisine yerleşmesi gerekecektir. Hatta bunun da
üzerine 7 ve 10 sayılarını da eklensin.
 |
| Seperate Chaining Simülasyonu |
Simülasyonda da görüldüğü üzere, dizide herhangi
bir yeni alan dahil etmeden elemanları bağlı liste şeklinde eklendi. Peki böyle
bir durumda, nasıl eleman arama yapılır? 13 sayısını arandığında, 13 mod 10 = 2
bulup dizinin 2. indisinde 13’de bulunur. Tek işlemde bulmak zor ancak bunu çok
büyük veri grupları içerisinde uyguladığını düşününce şuan daha küçük bir alanda
arama yapılıyor.
Seperate
Chaining Yönteminin Avantajları
- Uygulaması
kolaydır.
- Hash
tablosu asla dolmaz, sürekli yeni eleman eklenebilir.
- Bu
yöntem çoğunlukla kaç tane eleman ekleneceğinin bilinmediği durumlarda
uygulanabilir ve daha işlevseldir.
Seperate
Chaining Yönteminin Dezavantajları
- Bağlı
listeler üzerinde önbellekleme(cache) performansı çok iyi değildir. Open
Addressing bu durumlarda daha işlevsel kalır.
- Dizinin
boş alanları çöpe gider.
- Eklenen
sayılar sürekli benzer sonuç üretiyorsa yani sürekli modu aynı sonucu
veriyorsa hashing yönteminin hiçbir avantajı kalmaz, maliyet O(n)’e bile
gidebilir. (Worst case)
- Bağlı
liste kullandığımız için ekstra bir alan kullanırız.
Seperate Chaining yöntemi genel anlamda kaç tane
sayı ekleneceğini bilinmiyorsa, eklenecek verinin dizi sınırlarını aşma
ihtimali varsa kullanılmalıdır.
Open
Probing
Open Probing, Seperate Chaining’e alternatif bir
yöntemdir. Amaç yine hashing üzerinde çakışmaları çözmektir. Kendi içerisinde
ikiye ayrılır.
Lineer
Probing
Lineer probing, eğer hash tablosunda ilgili yer
dolu ise bir sonrakine bakmak ile ilgili bir çözüm sunar. Formülize edilirse
(h(x) + i) % s şeklindedir. s dizinin boyutudur. (Simülasyonda bu değer 10’du.
i ise 0’dan başlayan bir sayıdır. Hani ilgili yer boşsa i = 0 denemesinde
direkt yerleştirme yapılır.
Simülasyonda 93 sayısı eklensin. Elemanları (h(x)
+ i )% s formülüne göre yerleştirmek istendiğinde öncelikle 3. indise bakılır,
ancak dolu olduğunu görülüyor. (ilk adımda i = 0) Daha sonra i değerini 1’er
1’er artırıp kontrol ediyor ve doğru konuma yerleştirme yapılıyor.
 |
| Lineer Probing Simülasyonu |
Quadratic
Probing
Quadratic Probing hemen hemen linear probing ile
aynı mantıktadır. Tek farkı i değeri i^2 olur.
 |
| Quadratic Probing Simülasyonu |
{kind=link}
i sayısı yerine i^2 değerini kullandık. Aslında
amaç olası sıkışıklıklarda daha sonraki boş yerleri bulmaktır.
Şimdi bu iki mantığı birbirleri ile kıyaslayalım.
Seperate
Chaining
|
Open
Addressing
|
Uygulaması
kolaydır.
|
Uygulaması
zordur daha çok hesaplama gerektirir.
|
Hash
tablosu asla dolmaz, her zaman daha fazla eleman eklenebilir.
|
Hash
tablosu dolabilir, daha fazla eleman eklemk mümkün olmayabilir.
|
Çoğunlukla
kaç tane eleman ekleneceği bilinmeyen durumlarda kullanılır.
|
Genellikle
eleman sayısı belirli durumlarda kullanılır. Çünkü tablo dolduğunda yeni
eleman eklenemez.
|
Teorik
olarak tabloda pek çok boş alan kalabilir.
|
Tablodaki
tüm boşluklardan yararlanılabilinir.
|
Bağlı
liste kullanıldığı için ekstra alan kullanılır.
|
Herhangi
bir bağlı listeye ihtiyaç duyulmaz.
|
İkili Ağaç(Binary
Tree)
Ağaçların özel bir hali olan ikili ağaçlarda
her düğümün çocuklarının sayısı en az iki olabilir. Bir düğümün daha az çocuğu
bulunması durumunda (0 veya 1) ağacın yapısı bozulmaz. Yapraklar hariç bütün
düğümlerin ikişer çocuğu bulunması ve yaprakların aynı derinlikte bulunması
durumunda bu ağaca dengeli ağaç (balanced tree) denilir.
Hesaplama Karmaşılığı(Computational
Complexity)
Bilgisayar biliminde, bir algoritmanın hesaplama karmaşıklığı veya
basitçe karmaşıklığı, onu çalıştırmak için gerekli kaynak miktarıdır. Bir problemin hesaplama karmaşıklığı, bu
sorun için olası tüm algoritmaların (bilinmeyen algoritmalar dahil)
karmaşıklıklarının asgari düzeyidir.
Gerekli
kaynakların miktarı girdiye göre değiştiğinden, karmaşıklık genellikle n → f
(n) işlevi olarak ifade edilir; burada n, girdinin boyutu ve f (n)’ya en kötü
durum karmaşıklığıdır, yani n boyutunun tüm girdileri için gereken kaynak
miktarının maksimum değeri veya ortalama-durum karmaşıklığı, yani n boyutunun
tüm girdileri üzerindeki kaynak miktarının ortalamasıdır.
 |
| Notasyon Grafik Simülasyonu |
Açıkça verilen
algoritmaların karmaşıklığının araştırılmasına algoritmaların analizi,
sorunların karmaşıklığının araştırılmasına hesaplama karmaşıklığı teorisi
denir. Açıkçası, her iki alan da güçlü bir şekilde ilişkilidir, çünkü bir algoritmanın
karmaşıklığı her zaman bu algoritma tarafından çözülen sorunun karmaşıklığının
bir üst sınırıdır.
 |
| Big O Notasyonu CheatSheet |